Easy Static IP Configuration for Rancher Nodes

Right at the top I want to mention that the IP assignment aspect of this post and the solution I detail in it draw heavily from David’s work demonstrated in his post here: https://www.virtualthoughts.co.uk/2020/03/29/rancher-vsphere-network-protocol-profiles-and-static-ip-addresses-for-k8s-nodes/ In fact, they draw so heavily from it that I’d really consider the below an extension of his excellent work more than anything else. Please check it out and don’t miss his other great virtualization-related posts at https://www.virtualthoughts.co.uk/
TL;DR BLAH BLAH BLAH, JUST TAKE ME TO THE GOOD STUFF.
Background
Just to set the stage a little bit, here’s how I arrived at this problem.
Kubernetes
In my home lab one of my main areas of tinkering/researching is with Kubernetes. I’ve been pretty enthusiastic about Kubernetes ever since I first learned of it and have watched with great interest as it has evolved into the broadly-adopted solution it is today. After tinkering with some others, I settled on Rancher as my cluster manager both because it proved to be easiest to implement and because I knew I’d be working with it on the clock.
Infrastructure as Code – Cattle vs. Pets
One of my previous roles was as principal engineer, building my employer’s internal IaaS product. At least 60%-70% of the job was nuts and bolts, but a good chunk of it was also advocating for the use of the tools we were building and the adoption of Infrastructure as Code (IaC) practices and principles in various devops organizations. Occasionally in the course of spreading the word about IaC, I’d encounter some reticence or skepticism about its benefits; usually a thorough conversation was enough to swing folks to the side of modernizing their infrastructure management, but I also wanted to make sure that I really practice what I preach both in my day job and, at least as much as is practical, in my home lab.
One of the key concepts involved in IaC, and a refrain you’ve likely heard plenty of times by now, is treating your assets (VMs, especially) as “cattle, not pets.”
Even if you haven’t found the time to dive into them yet, you can probably imagine that IaC in general, and the even cattle vs. pets issue more narrowly, are huge topics. But the gist of it is that every piece of virtual infrastructure (again, especially VMs) you build should be disposable, ephemeral, and immutable, meaning you can build it, tear it down, and rebuild it very easily and all through automation — and while it’s running, you never change it. An excellent resource and perhaps the seminal work on the topic is Kief Morris’ Infrastructure as Code: Dynamic Systems for the Cloud Age, Second Edition, which I highly recommend.
A Real World Immutable Infrastructure Example
The “immutable” part of that is probably what throws most people for a loop. To help understand, and to give an idea of what immutable infrastructure really means in practice, here’s an example: I never patch my K8s nodes.
I can hear you now: “You never patch your machines?!? What are you, nuts?” I mean sure, yeah I probably am, but not because of that. Instead of patching my K8s VMs, I update the template and then rebuild the VMs using the new template. Once every few weeks — or when a critical security update for Ubuntu is released or I notice that a large number of patches are applicable to my nodes — I just build my Packer templates (see below.) And part of that process is to run apt upgrade, etc. so the templates are immediately current. From there I just scale the management node pool in and then — with the new template in place — back out one at a time, and then the same for the worker node pool. All told the process takes a couple hours of some low-touch manual work.
But why do that? I’ve got SaltStack managing all my VMs, including the K8s nodes, so why not just do something like…
salt -G 'os:Ubuntu' pkg.upgrade…and call it a day?
IaC Benefits
There are a bunch of benefits to embracing IaC and immutable infrastructure, and I again encourage you to check out Kief Morris’ book to understand the full range of advantages to the philosophy. But just using my example, here are some of the benefits I can think of off the top of my head about managing my nodes this way:
- Consistency – no configuration drift: I know that all my K8s nodes are all running with the exact same configuration. I don’t have to wonder if perhaps I applied one patch to some of them but not another, I know that they all have exactly the same OS build, I know I didn’t muck with any one-off configs in order to get it to work, etc. etc. This is absolutely critical in highly dynamic environments in which clusters frequently scale out and in.
- No “cruft”: The longer VMs run, the more “cruft” they accumulate: old log files pile up, things you only mean to live temporarily on the file system but forget might build up, artifacts from patches may be left around, software upgrades/installs/uninstalls can leave bits around… stuff like that just starts to clutter machines up. Every time I redeploy the nodes in my cluster, they’re all totally fresh — which is both an oddly satisfying feeling and makes isolating problems easier.
- Security concerns: Some things in that “cruft” could have security concerns associated with them: an old test config file with a password in it, a private key file you forget to delete, stuff like that. Cleaning everything up gets rid of that. And I know that if there is some kind of deficiency in the security posture of my VMs, I only need to find it and fix it in one place and then redeploy.
- Easier testing in lower environments: Just in the interest of full disclosure, I don’t actually do this often in my home lab. But using IaC does make it much, much easier to test new OS versions and configurations in a lower environment — because it’s all configured by code, you know you’re using the exact same OS configuration in, say, UAT that you will in Production. In that sense, you can start to think about the idea of “infrastructure versions” and treat infra as a dependency in almost the same way you’d treat a software dependency.
Obviously the list is much longer than that, but you can start to see how IaC pays off.
Isn’t This Kind of Overkill for a Home Lab?
In practice, IaC really boils down to doing more automation work up front to reduce operational toil and risk down the line. The truth, though, is that while there are some definite benefits to making everything disposable/ephemeral, the net technical benefit is highly dependent on a bunch of factors, and as relates specifically to a home lab, probably debatable. I mean let’s be honest: is going all-in on IaC really worth it in a home lab? Probably not, no.
But ultimately IaC (especially if you’re new to it) is probably as much about a mindset as it is any particular technology or tactic; you have to be religious about never reconfiguring anything. You have to break the habit of fixing a problem right where you find it and instead fix the source and rebuild. It almost has to become muscle-memory. And that, and not a direct operational benefit, is the biggest reason I try to follow IaC principles in my home lab: maintaining that mindset.
And perhaps the perfect, 100% rock-solid, for-sure, no-doubt use case for exercising that mindset and using ephemeral, disposable VMs is running Kubernetes nodes on vSphere.
Creating Fully Disposable K8s Nodes
For a while I kind of hemmed and hawed over what OS to use for my Kubernetes nodes. There are a number of different types of options: generic minimalist distributions, purpose-built, K8s-specific distros, and of course typical Linux distros. Ultimately I decided to go with the distribution I know best and use the most: Ubuntu.
Ubuntu, like most distros today, uses the powerful cloud-init package for the initial configuration of cloud instances. Rancher also enables the direct use of cloud-config YAML in its Node Templates, and that’s where most of the “magic” of this post will happen.
Script — or Template — All the Things
To make the IaC goal of immutable infrastructure a reality requires, as discussed above, automating the entire lifecycle of your VMs; of particular interest here is that every step required to create a VM that can be scripted or otherwise automated must be scripted or automated. In the case of Rancher nodes in my home lab, at a high level, that list of steps looks like this:
- Layout the physical components of the VM and some OS options: CPUs, memory, network interfaces, storage devices/volumes, locale, keyboard, etc.
- Configure basic services like SSH
- Install a bunch of packages, perhaps adding apt repos
- Configure system user accounts and permissions (sudoers, etc.)
- Give the system a hostname
- Acquire an IP address (hint hint)
- Configure networking (assign IP to interface, configure gateway, netmask, DNS servers, search order, etc. etc.)
- Register host/IP in DNS
- Add host to monitoring system (checkmk in my case)
- Add host to configuration management system (SaltStack in my case)
And that all should or has to happen before Rancher starts doing its thing to configure the VM as a K8s manager or worker node in the cluster.
(And that’s just the start of the VM’s lifecycle… I haven’t even mentioned the end of its lifecycle, which is also a thing.)
So even in my pretty limited use case, that’s a lot of… stuff that has to happen in order to get a VM online. The good news is that there are tools to help manage it all, and they work at three different phases of the VM’s creation: the templating, the initial configuration, and online configuration management.
In my case, I tackle most of the work in the template and the rest in the initial configuration. Online config management (using SaltStack) is in the picture as kind of a backstop or means to true-up any accidental drift or correct anything I may botch.
Templates/Images
For creating my templates, I use Packer. I won’t go into great detail here, as maybe it’s a topic for another post. But this is really where the bulk of my configuration happens, and you can check out my templates in this Github repo:
https://github.com/mconnley/ubuntu-packer
Using cloud-config YAML
From there, it’s up to Rancher to take the cloud-config YAML specified in the Node Template and apply it in each new instance it spins up. Some things here can get a little tricky timing-wise, but if you really run into some timing issues, as I did, you can always bail out and write scripts and configure them to execute with specific timing using at.
Online Config Management
Once my VMs are fully online, the Salt minion spins up and connects to my Salt master. I have Salt states for each of the OSes I use which do some basic things like ensure user accounts from the build process aren’t left over, the user accounts I need are present, CA certs are installed, NTP is configured, some services are disabled/masked, stuff like that. That way if I’m ever in doubt about the state of some of the most critical configs on my VMs, I can do …
salt '*' state.apply…and know that at least some minimal configs will get set.
I’d suggest against using this for anything more than a backstop, though. At minimum, using something like SaltStack to actually do your builds could introduce some funky sequencing issues or necessitate some manual intervention (you’re not auto-accepting Salt minion keys, are you?) to make the builds succeed. You don’t want any of that. And I won’t go so far as to say that when it comes to IaC that it’s truly anti-pattern, but it sure feels like it is. Instead, you should…
(Almost) Always Put It In the Template
A question that became a frequent topic of conversation in a previous role of mine was, “What belongs in the template/base image vs. what belongs in the scripts we run at deployment?”
Of course the answer to this is going to vary from scenario to scenario and organization to organization. But in my mind, the short answer has always been that if it can go in the template, it should go in the template.
Why?
It’s About Time
The first reason for that is time. In many cases — certainly my home lab is among them — the amount of time it takes to fully provision a VM isn’t a big consideration. But in a critical production environment that depends on being able to horizontally scale VM-based deployments and do it fast, it can matter a great deal. The time it takes to execute configuration steps at deployment time adds up quickly, with software installations of course being the most time consuming. Pushing software installs into the template removes those steps altogether.
Don’t Let Others Bork Your Builds
The other main reason is reliability. If you’re installing packages, chances are they’re coming from some remote repository. What happens if that repo is down or slow or you’re having network connectivity issues? Your VM build crawls — or if properly strict controls/checks are in place, it doesn’t get built at all. That’s, uh, a problem, and one I’ve seen happen.
DRY
Also it’s just inefficient. If you’re installing software at deployment, and it’s coming from a remote repository, you’re going to be downloading the same bits, what, hundreds of times? Thousands of times? Hundreds of thousands of times? Total waste of electrons. Don’t Repeat Yourself: Download it once, install it into your template, and that’s it.
Yes, It Can Go in the Template. Yes, Really.
I’d encounter a sysadmin or dev here and there who would insist that the only way to install a given package was to do so once the VM was fully built and online. There were some instances in which maybe that was at least plausible (particularly on Windows) but for the most part… it’s baloney. Usually there’s a way to fully install — although perhaps not fully configure — the package. And even if there’s not you should at least consider getting the bits into the image for eventual installation at build time.
The Problem
So I’ve covered the background, some Infrastructure as Code principles, how I go about creating truly disposable nodes, and when you should put software installs in your images/templates. (Always. The answer is always.) That’s all well and good, but there’s a ton of articles out there that go over all that stuff. What’s the real interesting (to me, anyway) problem I’m going after here?
Assigning IP Addresses to Rancher Nodes
So you’ve got your template ready (you installed all your software packages in it, right?), you’ve got your cloud-config YAML doing what you want it to, and you’ve got a configuration management system ready to control any drift. Great. You start walking through the basics of what will need to happen to get a VM online such that Rancher can SSH into and configure it. Here’s a very high-level list:
- Create a hostname – Rancher handles that for you, using the Name Prefix for each Node Pool
- Build the virtual machine – Rancher does that too, and will request vCenter to build the VM according to the Node Template
- Connect it to a network – the VM gets connected to the port group you specify in the Node Template, no problem there
- Get an IP address – Uh-oh!
And we’ve arrived at our problem. How do you reliably get addresses for your VMs in a way that’s manageable and, of course ideally, automatic? There are a couple not-great options and then the one this article is about. Let’s look at the not-great ones first:
DHCP
What’s so bad about DHCP, you might ask? Well, there’s nothing really all that bad. But it does at least add a few factors to consider.
First off, it’s another dependency — it’s yet another service your VM needs to be available in order to provision successfully. Sure, DHCP is built to be very redundant, resilient, highly available, etc., and I’m sure most environments that rely on it have built implementations that are basically bulletproof. Fine! But even so, it’s still another dependency on the list.
Plus you’re almost certainly going to want to use DHCP reservations. You’re inevitably going to end up with a bunch of them — and what happens to each reservation once its associated machine is destroyed?
Issues with Decommissioning
The entirety of this post has dealt with the start of a VM’s lifecycle. This is a good point to bring up some issues that come along with ending its lifecycle. As much as there is that goes into making a VM, in some aspects destroying it is actually a little more complicated.
Rancher does a good job of allowing you control over creating VMs: you can do quite a bit with the cloud-config YAML in your Node Templates, for example. And creation is inherently easier to deal with in that you can customize the template/image to begin with, and then once Rancher lays down a new instance, the sequence from there is pretty well-known.
But while there’s a clear trigger that sets off a known series of events when the machine is created, Rancher doesn’t — at least as far as I’m aware — have a facility for triggering events during the destruction of a node. So taking the example of DHCP reservations above, there’s no opportunity for you to instruct Rancher or the node being decommissioned to execute a script to, say, delete its DHCP reservation. So you could be left with a bunch of artifacts of dead VMs which, especially in larger environments, is a problem.
So Rancher just isn’t great, from what I can see, at handling anything at that end of the lifecycle. In the case of my home lab, what I’ve done to mitigate that problem is to give extra attention to my provisioning scripts to check for conflicting artifacts when they run. More detail on that later, but this is another area in which the best solution makes things easier.
Static IPs – But How?
So let’s cross DHCP off the list. That leaves assigning static IPs to each machine as it gets built. First of all, the only way I can even think of doing that is to log into the console of the VM and manually assign it an IP while Rancher is still waiting for it to come online. That’s so very bad enough on its own that we don’t even have to discuss that it also involves manually tracking IPs which should always be avoided if possible.
It’d be great if Rancher had some kind of simple mini-IPAM feature to distribute IPs to nodes from a pool. But it doesn’t, and even just spit-balling some other ideas doesn’t yield a solution that feels anything better than completely hacky.
If only there were some other service that could manage and distribute a pool of static IPs, and deliver them into the running OS itself somehow…
Network Protocol Profiles
Well, it just so happens that’s exactly what Network Protocol Profiles do:
A network protocol profile contains a pool of IPv4 and IPv6 addresses. vCenter Server assigns those resources to vApps or to the virtual machines with vApp functionality that are connected to the port groups associated with the profile.
You can configure network protocol profile ranges for IPv4, IPv6, or both. vCenter Server uses these ranges to dynamically allocate IP addresses to the virtual machines within a vApp, when the vApp uses transient IP allocation policy.
Network protocol profiles also contain settings for the IP subnet, the DNS, and HTTP proxy servers.
As I was thinking about how to deal with this issue, a vague recollection of “IP Pools” for vApps from way back in probably the vSphere 5.x days popped into my head. But I’ve never really worked much with vApps and I wasn’t fully putting the pieces together, so as I was Googling it, I ran smack into David’s post which not only is a perfect example of how to use Network Protocol Profiles (which essentially replaced IP Pools, to my understanding) but also directly addressed the specific challenge I was dealing with. So I’ll again refer you to David’s post here: https://www.virtualthoughts.co.uk/2020/03/29/rancher-vsphere-network-protocol-profiles-and-static-ip-addresses-for-k8s-nodes/
His article shows the basic nuts and bolts of getting this solution working, and it was all I needed to fully solve the issue in my environment. But I wanted to dive a little deeper into how exactly it works and better understand the mechanisms involved.
vApps & OVF Environment Variables
The first thing that’s critical to understand for this scenario is how vApp options can be used to pass information into a running virtual machine.
Basically you can use vApp Options to create custom properties for a VM which then get inserted by vSphere/vCenter into the guestInfo.ovfEnv VMware Tools variable. (Alternatively, you can opt to present the OVF environment doc as an ISO that gets mounted to the VM’s CD-ROM.) From there, you can use commands within the VM to retrieve those values.
A Simple Example
Just to demonstrate this functionality — and give you a look at the basic mechanics Rancher is using under the hood in this solution — I’ve created an Ubuntu Jammy VM from a template, and I’ll enable and configure vApp Options for it. But first, before I enable vApp Options, let’s take a look at what this command returns:
vmtoolsd --cmd 'info-get guestinfo.ovfEnv'
If we take a look at the documentation, we can see this is the syntax to use to “query information such as version description, version string, build number, and so on.” Essentially what it’s doing is querying the “ovfEnv” variable, which is a member of the “guestinfo” variable. But because I haven’t yet enabled vApp Options for this VM, that variable is empty. So now I’ll enable vApp Options on the VM’s Configure tab, and then select “vApp Options” and “EDIT…”:
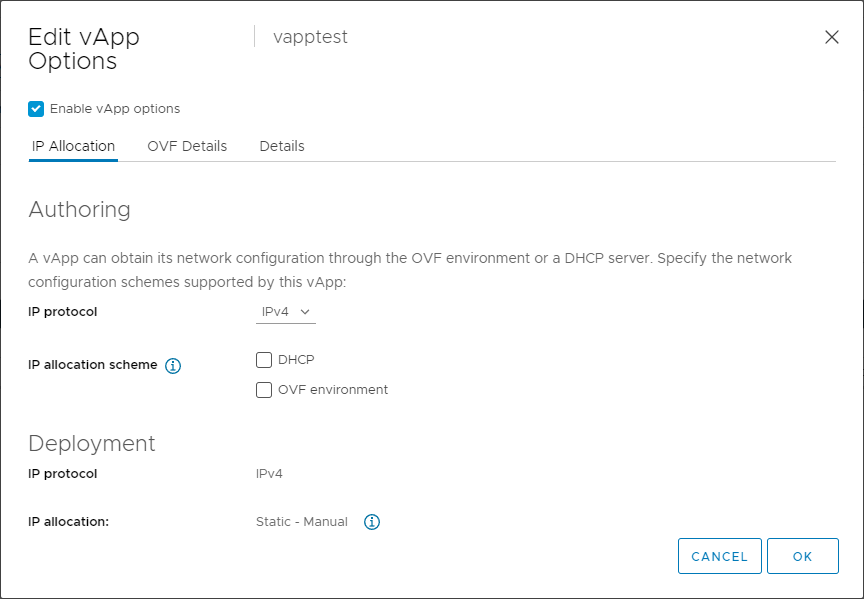

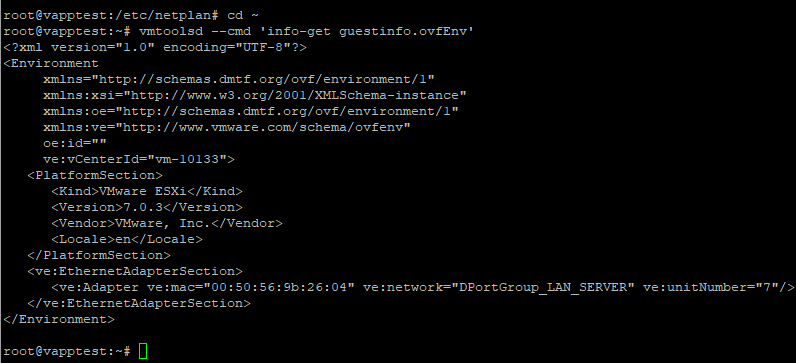
For changes to vApp options to become effective, the VM has to be power cycled. A reboot won’t do it. After that, though, you can see the same command returns the ovfEnv variable, which is a chunk of XML:
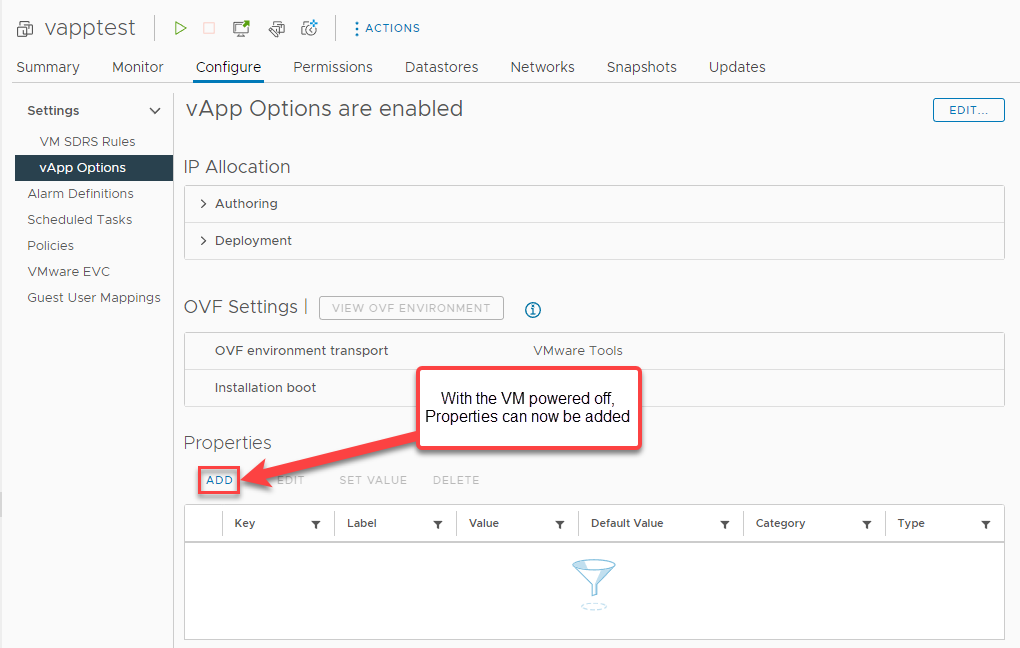
Cool. Now how do we pass the values that we want into the VM? Keeping with the theme of vApp options and power cycling, we’ll need to shut the VM down for the next step. Once it’s shut down, in the vApp Options section of the Configure tab, you’ll see we can now add Properties:
Let’s add a Property and see what that looks like…
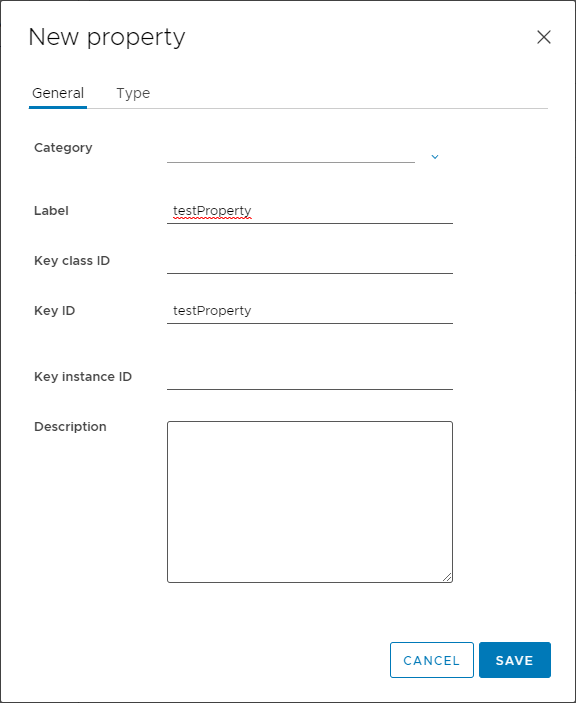
The General tab is pretty basic. You can create Keys hierarchically using Key Class ID, KeyID and Key instance ID, but at least in this case, just a Key ID will suffice — I’m using “testProperty”.
The Type tab has a little more substance to it:
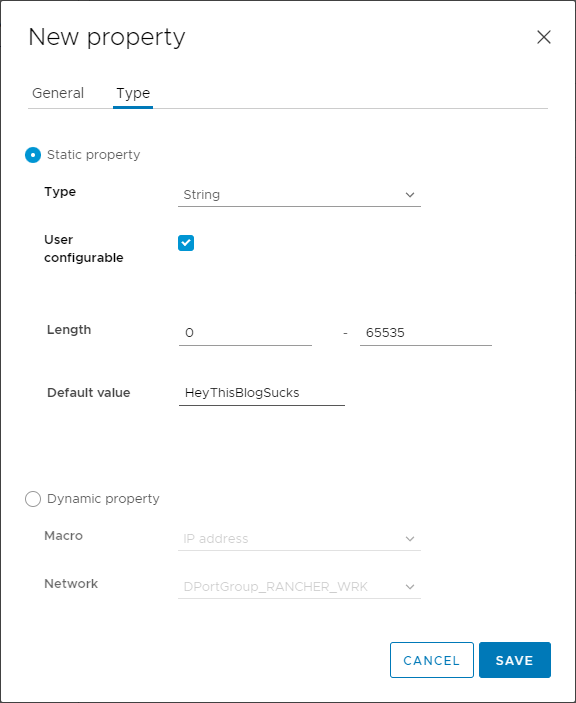
There’s a lot to unpack here, but just for starters/grins I’m going to select a Type of String and give it a Default value and save it. It now appears in the list of Properties:
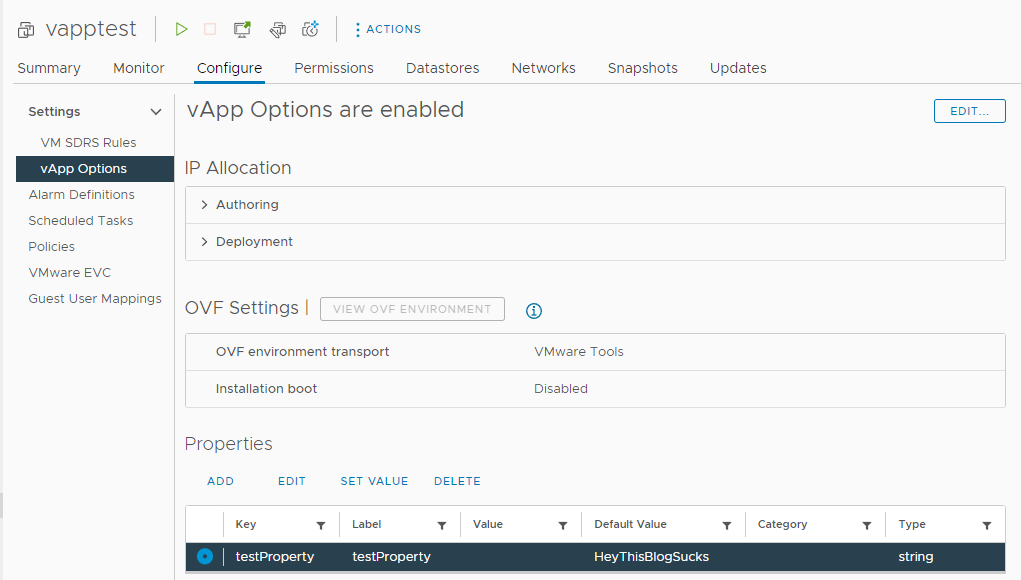
We can edit it, or delete it or set a value for it — again, only while the VM is powered off:
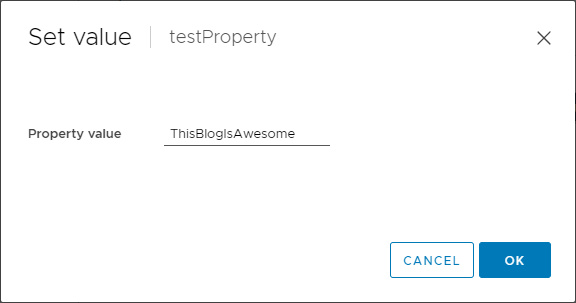
Now I’ll power on the VM and let’s see what happens when we run that same vmtoolsd command:
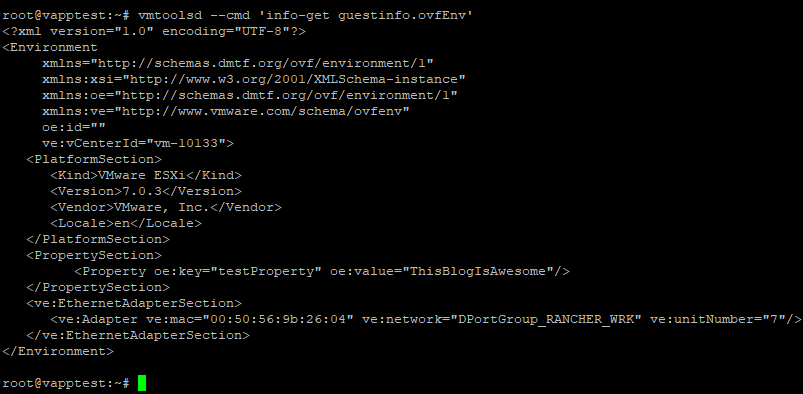
That’s all there is to passing values from vCenter into a VM. There are a number of options for creating Properties and defining their respective value Types, and there’s a great deal of configurability available. For example, if your use case called for it, you could select a “String choice” type to allow users to select from a choice list. Also numeric types like Integer and Real allow you to define a range of valid values. There are a few things like that, though most more directly pertain to full-fledged vApps rather than just VMs. But check out the full list of types and their capabilities; they might come in handy. The only description of each type that I’ve been able to find is here: https://vdc-repo.vmware.com/vmwb-repository/dcr-public/1ef6c336-7bef-477d-b9bb-caa1767d7e30/82521f49-9d9a-42b7-b19b-9e6cd9b30db1/vim.vApp.PropertyInfo.html It is definitely not the best doc and it’s more focused on configuring Properties via the vSphere API, but there are nevertheless some valuable pieces of information there.
But let’s take another look at some of the other options for setting — or more accurately, deriving — the value of a property.
Dynamic Types and Other Metadata
In the example above, I passed an arbitrary string value into the OVF Environment document which can then be consumed by scripts/automation within the VM. While that’s helpful for showing the underlying mechanisms involved, it doesn’t directly address our problem. Ultimately what we need is an IP to be assigned from the Network Protocol Profile’s IP pool and pass it, along with all the other relevant network config values (gateway, netmask, DNS servers) into the OVF Environment, just like the strings above were.
I already have a Network Protocol Profile created and associated with the distributed port group to which my test VM is connected. Here’s a quick look at it:
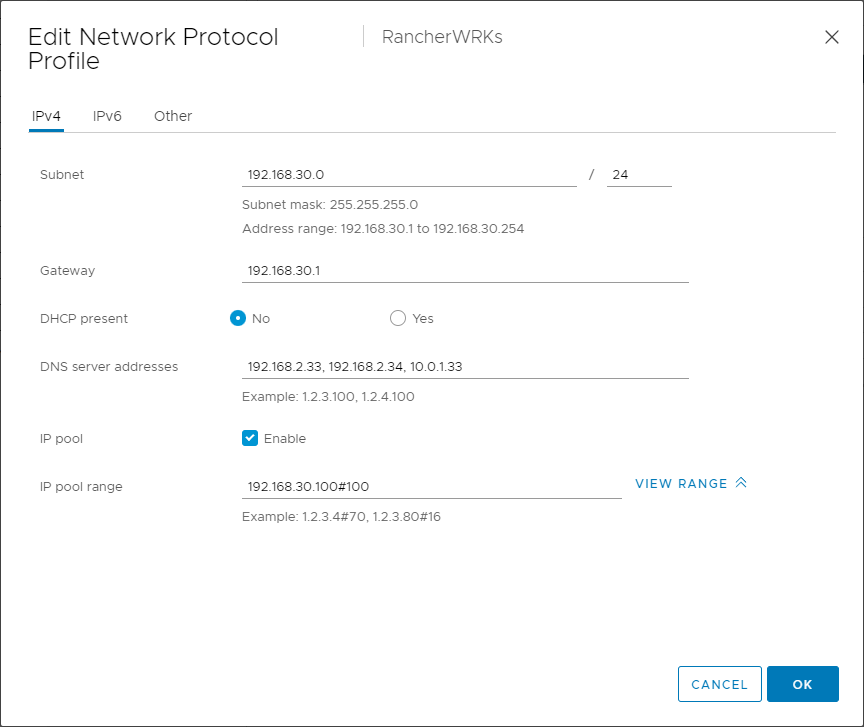
As you can see I’ve created a 100 address IP Pool beginning with 192.168.30.100 on my 192.168.30.0/24 network and specified the gateway as .1 and provided my DNS servers. I also set the DNS domain and DNS search path values on the Other tab to mattconnley.com (not shown.)
Going back to the vApp Options Edit dialog of for the test VM, here is where the IP Allocation tab comes into play. Selecting “OVF Environment” enables the selection of a Deployment option. To use the pool specified in the NPP, select “Static – IP Pool”:
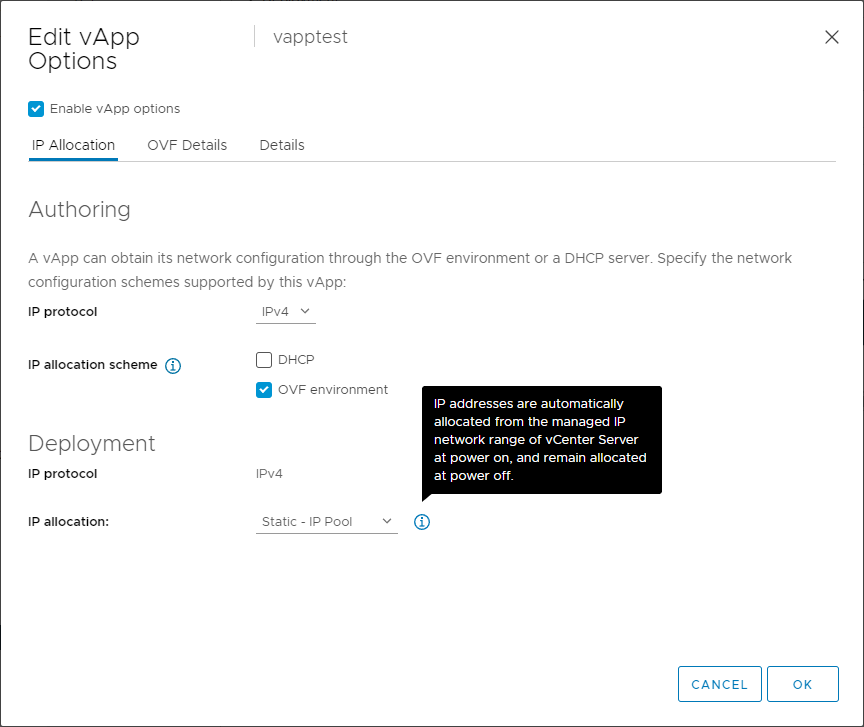
The tooltip tells the story here: clearly we don’t want “Static – Manual”. And we also don’t want “Transient – IP Pool”, because that allocation strategy will reallocate IP addresses on every boot. “Static – IP Pool” does exactly what we want: it allocates an IP from the pool when the machine is first powered on and keeps that IP assigned to the VM until it’s deleted.
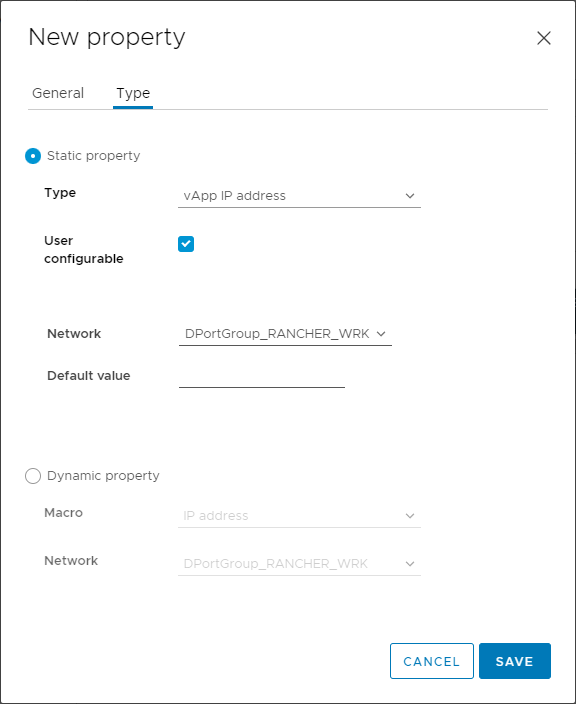
Now I’ll add a new “testIpAddress” Property to the VM and select “vApp IP address” as its type. As you can see, it selects the Distributed Port Group to which the VM is attached — functionally, this associates the property with the Port Group’s NPP:
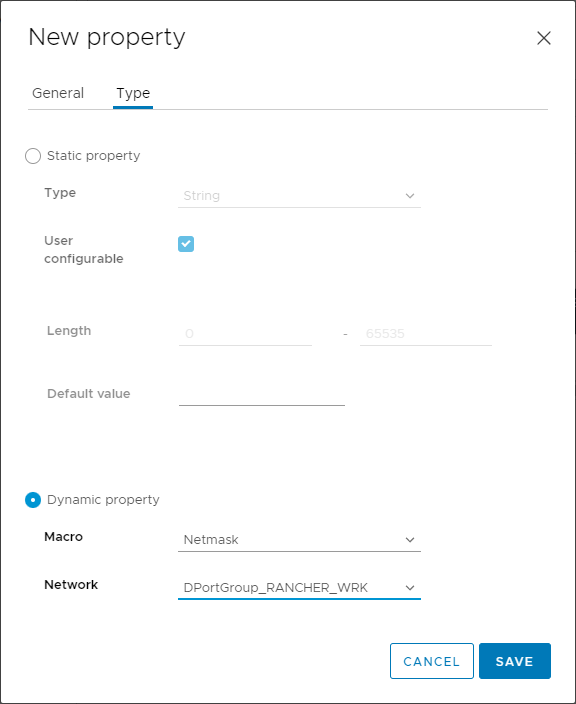
I’m also going to add a property for the netmask, named “testNetmask”. For its value, I’m going to select the Dynamic Property “Netmask”. Again you can see it selects the VM’s Port Group which is associated with my NPP:
Back at the properties list of the VM, you can see all three properties we’ve created. Make special note of the Type of testIpAddress and the Default Value of testNetmask (which is of type “expression”):
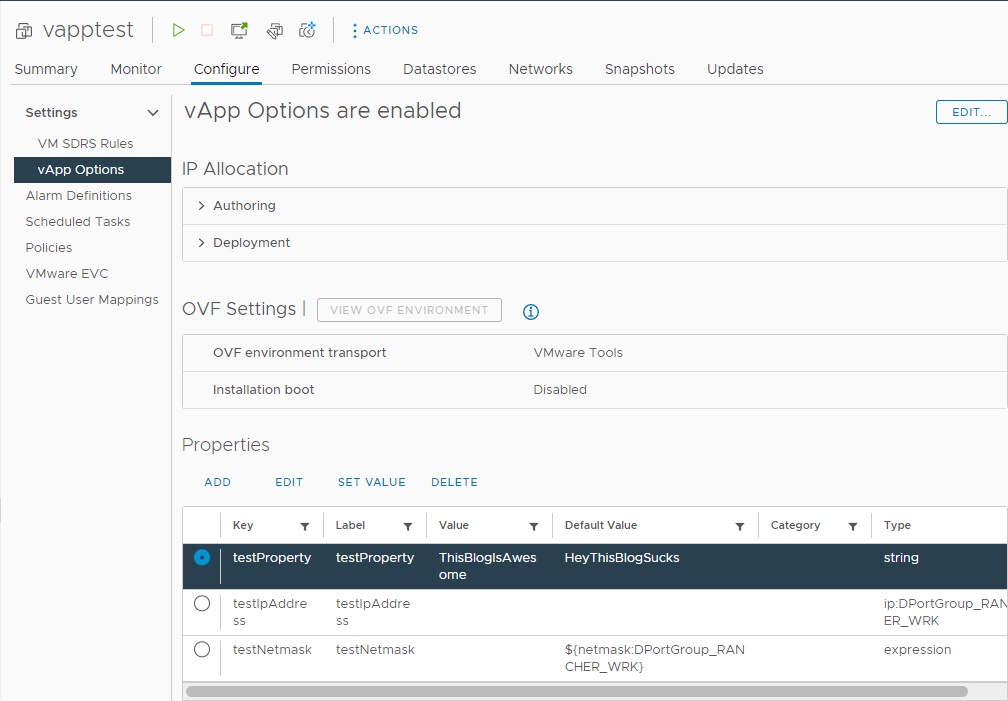
Let’s power on the VM and see what happens when we query the OVF Environment document now:
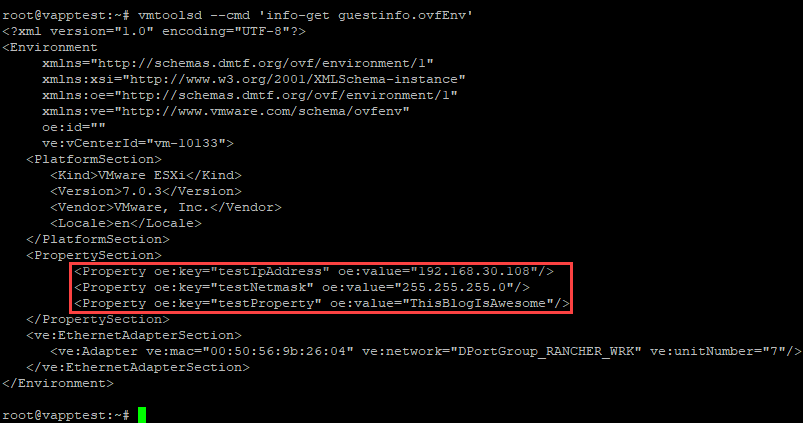
testIPAddress is set to 192.168.30.108, which was assigned by vCenter from the NPP’s address pool, and testNetmask contains the NPP’s configured netmask. And 192.168.30.108 will be assigned to this VM until it’s destroyed! Exactly what we wanted!
Putting It All Together: Associating Rancher Node Templates with NPPs
We’ve seen now how vCenter can pass values to VMs via the OVF Environment, and how we can source those values from the Distributed Port Group’s associated NPP. Now all that’s left is to configure Rancher to build each node using the vApp Options we want.
Configuring the Node Template’s vApp Options
I’m going to skip discussing the details of creating a vSphere Node Template as that’s pretty straightforward. And before touching on the Cloud Config YAML, I’m going to skip down to the vApp Options section of my Node Template:
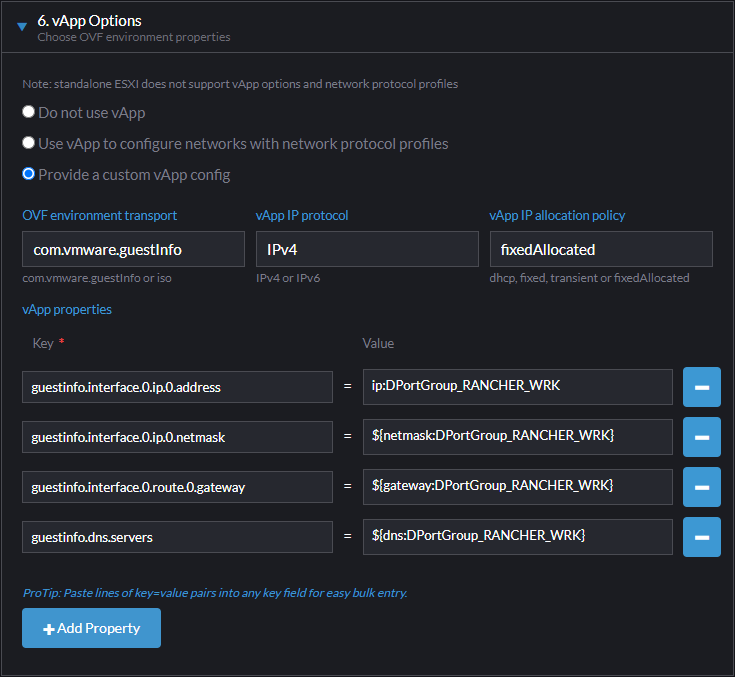
The first thing to note here is that the documentation is pretty sketchy when it comes to choosing “Use vApp to configure networks with network protocol profiles” vs. “Provide a custom vApp config”. From what I can gather, choosing “Use vApp to configure…” may work in some scenarios, but it appears to overwrite any other Cloud Config you provide. So because we have to do a bunch of stuff with Cloud Config, want to go with “Provide a custom vApp config.”
From there, it should be pretty easy to see the relationship between what we’re looking at in the Node Template and what we’ve discussed to this point:
- OVF environment transport – Specifies whether to deliver our values via an ISO or via VMware Tools
- vApp IP protocol – Specifies IPv4/v6 for IP Allocation
- vApp IP allocation policy – Specifies IP allocation strategy (we want Static – IP Pool which = “fixedAllocated”)
- vApp properties – The list of property names or expressions and the keys we want to use to pass them into the OVF Environment
We know those values will be there when we execute:
vmtoolsd --cmd 'info-get guestinfo.ovfEnv'All that’s left now is to use them.
Use Cloud Config to Configure the Network
I’ll once again point you to to David’s post as he describes it as well as or better than I can: https://www.virtualthoughts.co.uk/2020/03/29/rancher-vsphere-network-protocol-profiles-and-static-ip-addresses-for-k8s-nodes/
The short version is that the Cloud Config YAML will read the values out of the OVF Environment, write them to a file for parsing, and then use the parsed values to build a netplan file which it then applies. The VM comes online with the IP from the NPP’s pool and Rancher goes on and configures it. My full Cloud Config YAML is posted below, but…
That’s it!
Notes and Closing Thoughts
I hope you’ve found the above informative. David’s post does a great job of explaining the “what” of the solution, and hopefully my attempt to dive into the “how” and the “why” was of some value. Here are a couple additional notes based on my experience along the way:
Keep the Network Layout Simple
When I first started implementing this solution, I had an unnecessarily complex network design in mind. In my head I concluded, “One Network Protocol Profile = one Distributed Port Group, and one Distributed Port Group = one VLAN, so I need two VLANs.” What I wound up with was fine — right up until the first time I had to update and reboot my router…
In reevaluating it I realized that the second half of my thought process above was wrong; of course multiple Port Groups can live on the same VLAN. I converged everything back onto one VLAN which obviously makes a lot more sense. So don’t make that mistake at the very least. And actually, in thinking about it, there’s really no significant reason for me to even keep my manager (etcd/ControlPlane) and worker nodes in separate pools anyway.
Clear Up Old Artifacts at Build Time
As I mentioned above, Rancher doesn’t seem to have any facility for executing scripts or other automation when it destroys a node. (By the way, if I’m wrong on that, somebody please set me straight.) So the only other option, then, is to make sure that when the node comes online, it clears up any artifacts and thus eliminates any potential conflicts on its own.
So at a high level, I need my Cloud Config to do a few things:
- Configure the network using the vApp Options (I’ll post my full Cloud Config below, but won’t dive into this as it’s already well covered)
- Wait for the VM’s hostname to get set
- DELETE any DNS A or PTR records for that hostname
- ADD DNS A and PTR records for the hostname
- DELETE the host, if it exists, from the monitoring system (checkmk)
- ADD the host to checkmk
- Enable and Start the Salt minion
The trickiest part was getting the timing right. Basically what I do is using at, I create and schedule the script to run at +2 minutes. Then I wait to make sure the hostname isn’t still set to “localhost” and then proceed with the rest of the tasks.
Some of the code is a little sloppy and I’ve redacted some passwords, but here’s my full Cloud Config YAML:
#cloud-config
write_files:
- path: /root/postbuild_main.sh
content: |
#!/bin/bash
rm /usr/local/bin/postbuild_job.sh -f
vmtoolsd --cmd 'info-get guestinfo.ovfEnv' > /tmp/ovfenv
IPAddress=$(sed -n 's/.*Property oe:key="guestinfo.interface.0.ip.0.address" oe:value="\([^"]*\).*/\1/p' /tmp/ovfenv)
SubnetMask=$(sed -n 's/.*Property oe:key="guestinfo.interface.0.ip.0.netmask" oe:value="\([^"]*\).*/\1/p' /tmp/ovfenv)
Gateway=$(sed -n 's/.*Property oe:key="guestinfo.interface.0.route.0.gateway" oe:value="\([^"]*\).*/\1/p' /tmp/ovfenv)
DNS=$(sed -n 's/.*Property oe:key="guestinfo.dns.servers" oe:value="\([^"]*\).*/\1/p' /tmp/ovfenv)
PTRName=$(echo "arpa.in-addr.$IPAddress" | awk -F. '{print $6"."$5"." $4"."$3"."$2"."$1}')
cat > /etc/netplan/01-netcfg.yaml <<EOF
network:
version: 2
renderer: networkd
ethernets:
ens192:
addresses:
- $IPAddress/24
gateway4: $Gateway
nameservers:
addresses: [$DNS]
search: [mattconnley.com]
EOF
sudo netplan apply
echo "bash /root/nsupdate.sh" | at now + 2 minutes
- path: /root/nsupdate.sh
content: |
#!/bin/bash
vmtoolsd --cmd 'info-get guestinfo.ovfEnv' > /tmp/ovfenv
IPAddress=$(sed -n 's/.*Property oe:key="guestinfo.interface.0.ip.0.address" oe:value="\([^"]*\).*/\1/p' /tmp/ovfenv)
PTRName=$(echo "arpa.in-addr.$IPAddress" | awk -F. '{print $6"."$5"." $4"."$3"."$2"."$1}')
HOST=`hostname`
host=`hostname`
LOCALHOST=localhost
COUNTER=0
until [$COUNTER -gt 60]
do
echo $HOST
if [[ "$HOST" == "$LOCALHOST" ]]; then
echo "Invalid hostname. Waiting..."
sleep 2;
else
break
fi
done
echo "update delete $HOST.mattconnley.com A" > /var/nsupdate.txt
echo "update add $HOST.mattconnley.com 300 A $IPAddress" >> /var/nsupdate.txt
echo "" >> /var/nsupdate.txt
echo "update delete $PTRName PTR" >> /var/nsupdate.txt
echo "update add $PTRName 300 PTR $HOST.mattconnley.com" >> /var/nsupdate.txt
echo "send" >> /var/nsupdate.txt
nsupdate /var/nsupdate.txt
checkmkfqdn='redacted.fqdn.com'
checkmksite='some-site'
checkmkusername='someusername'
checkmkpassword='supersecurepassword'
deleteurl="http://$checkmkfqdn/$checkmksite/check_mk/api/1.0/objects/host_config/$host"
posturl="http://$checkmkfqdn/$checkmksite/check_mk/api/1.0/domain-types/host_config/collections/all?bake_agent=false"
body_template='"folder": "/", "host_name": "%s", "attributes": {"labels": {"k8swrks": "true"}}'
body_json_string=$(printf "$body_template" "$host")
auth_template='Authorization: Bearer %s %s'
auth_header=$(printf "$auth_template" $checkmkusername $checkmkpassword)
curl --fail -X 'DELETE' "$deleteurl" -H 'accept: */*' -H "$auth_header"
curl -X 'POST' "$posturl" -H 'accept: application/json' -H "$auth_header" -H 'Content-Type: application/json' -d "{ $body_json_string }"
cmk-agent-ctl register --hostname $host --server $checkmkfqdn --site $checkmksite --user $checkmkusername --password $checkmkpassword --trust-cert
systemctl enable salt-minion
systemctl start salt-minion
rm /root/postbuild_main.sh
rm /root/nsupdate.sh
runcmd:
- bash /root/postbuild_main.shThe net result is that the only manual step I currently have to make sure to do when I delete a node is to delete its key from my Salt master. I may automate that in the future as well.
Enjoy!